TfIdf-Vectorize long text in Python with Sklearn
Introduction
It is a common topic in Data Science and Machine Learning to transfer human language into machine language. A popular solution is using vectorizing techiniques (Convert into 0-1 array).
Recently I am learning Data Science and Machine Learning, here are my experience of TfidfVectorizer.
In Python, there are two common ways to vectorize using sklearn. Tfidf and Counting vectorizing.
Count vectorizing is pretty simple, here we will emphasize on TfIdf.
TfIdfVectorizer
TfIdf is the abbreviation for term frequency * inverse document frequency.
Here is an official explaination for Tfidf
The idea is that rare words are more informative than common words. (This has connections to information theory).
Hence, the definition of tf-idf is as follows. First:
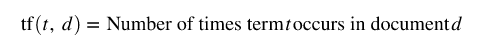
Next, if N is the total number of documents in the corpus D then:
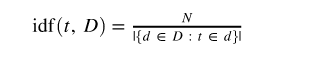
where the denominator is the number of documents in which the term t appears. And finally:
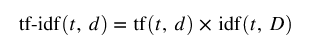
Example
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(min_df = 1)
D = vectorizer.fit_transform(str_list)
min_df is the minimum occurrence time, we can also set a series of parameters like max occurrence, etc. You can refer TfIdf Official Doc for more reference.
The above code is the simpliest code to vectorize a document. Where str_list is a series of string. For example
str_list = ['I am study data science', 'I am study machine learning']
In this case, Document is I am study data science and I am study machine learning.
D.toarray()
Transfer D to an array, it is a m * n array. m is the longest string’s length. n is number of strings. For element D[i, j], i represents row, which is also the corresponding text, j represents column, which is also the corresponding term. It’s rescale from 0 to 1, so it’s pretty hard to tell what’s the difference.
But if we use D times DT
X = D*D.T
We get a 2 * 2 array, which is the cosine distance for each text. Here is the magic, now we have an array for the distance for each text. Try yourself, find the amazing~
Furthermore, we can use
_idf
attribute to see the weight of each feature(item), use
get_feature_name
to see each item and get the corresponding weight. Here the Official Document gives detailed explaination for this.
Resources
Here is another very good explaination in Stackoverflow
You can also see the whole example in my github