K Means Algorithm
Introduction
K-Means++ is a common algorithm in clustering. It’s an essential algorithm in data mining and Machine Learning. K-Means++ is origin from K-Means algorithm. This post discuss the nature of K-Means and K-Means++, and the reason why K-Means++ is better.
K-Means Algorithm
K-Means or K-Means++ are algorithm for clustering. Given a number of candidates, and given a specific number of groups, K-Means will calculate the similarity of each points and clustering them into specific number of groups.
- Random initialization
- Clustering
- Repeat the previous steps for many times and take the best result
Sample execution
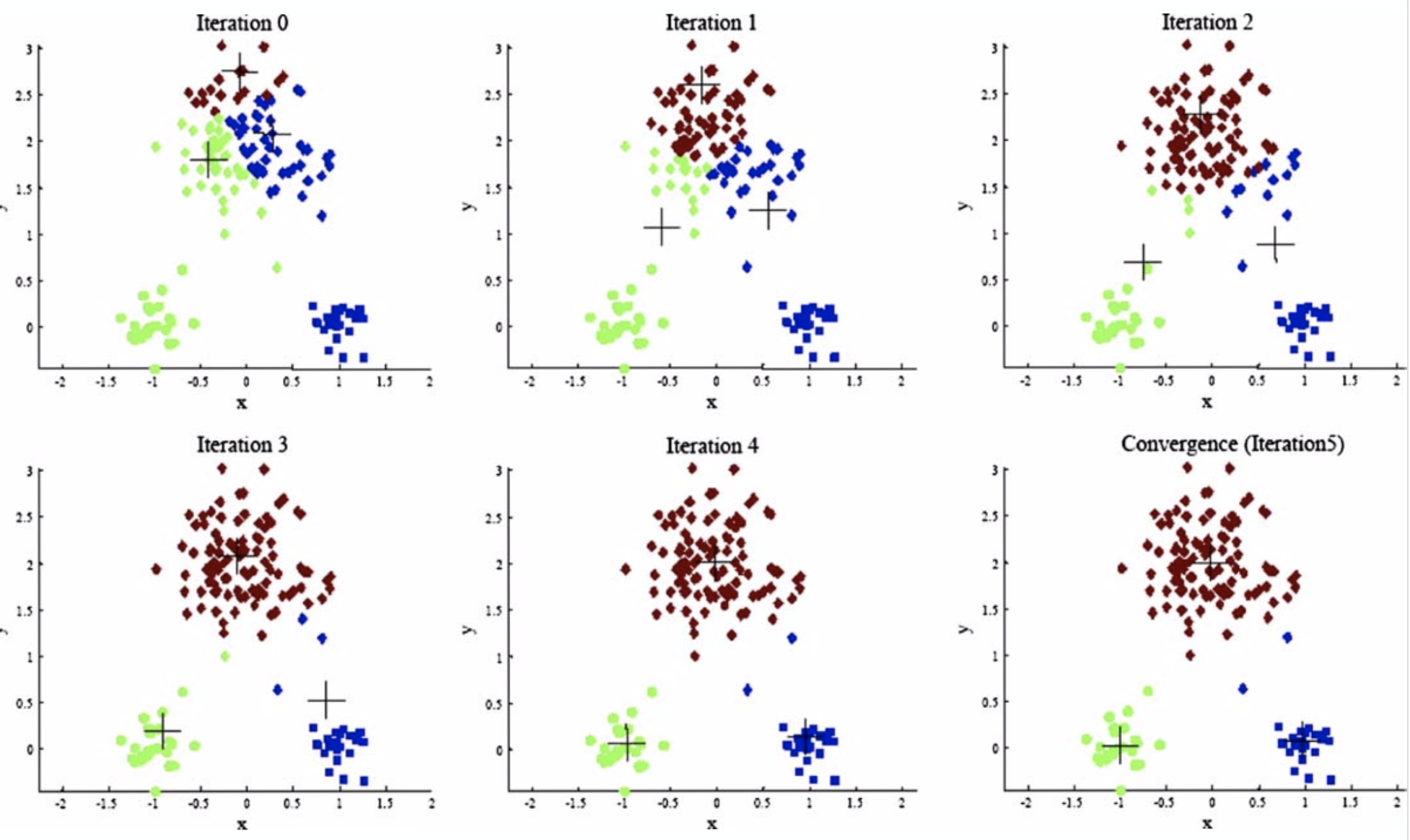
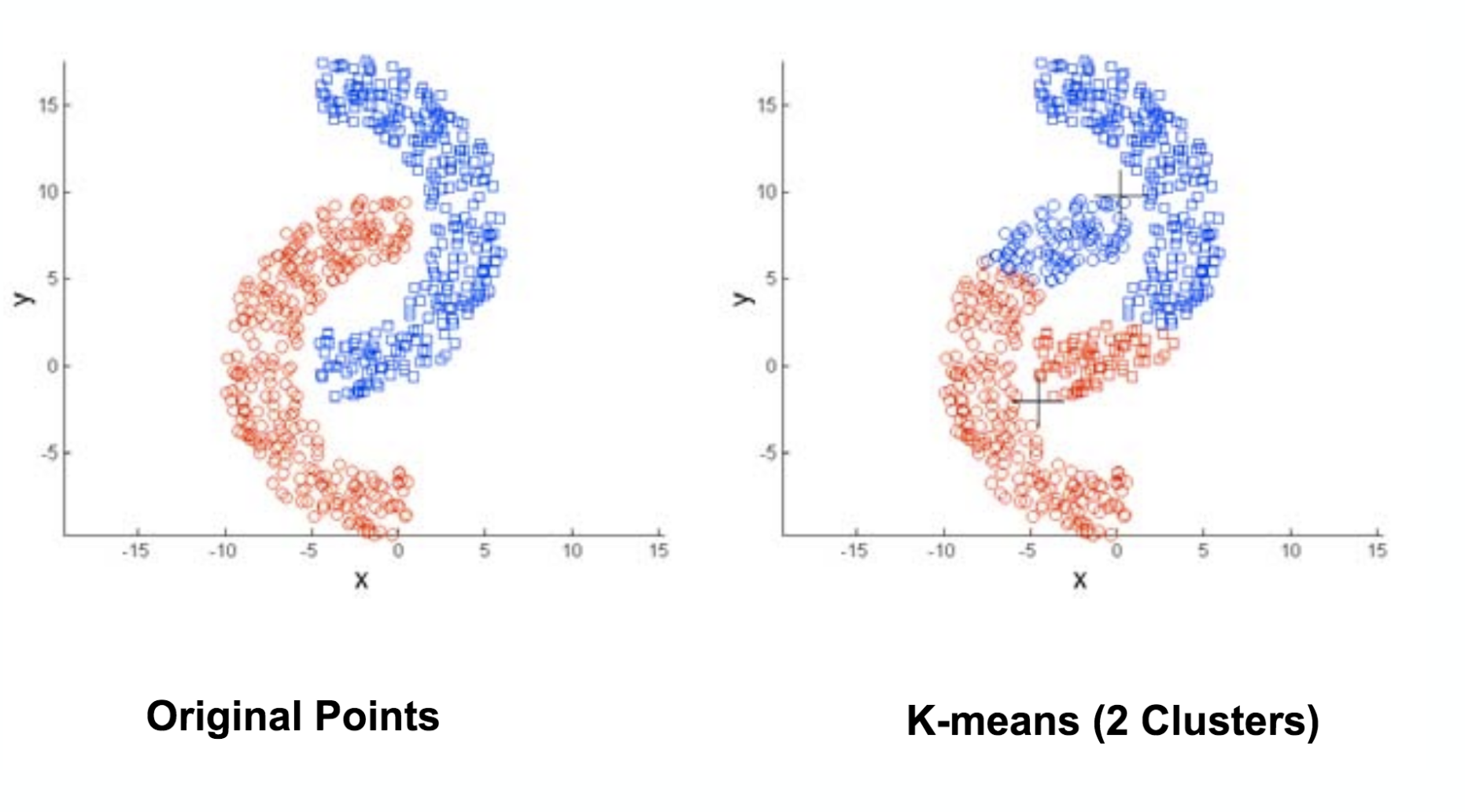
The choice of initialization point differs
With different initialization point, K-Means algorithm can have very different execution result.
K-Means++ Algorithm
- Initialization phase
- Choose the first center at random
- Choose next center with probability proportional on D^2(x)
- Iterate phase
- iterate as in k-means algorithm until convergence
Code source
You can also refer my github code source for K-Means++ real data example.